


项目分享| 仅需1板卡+1摄像头,3步完成人脸喜怒哀乐识别
面部表情识别系统可用于多种应用,可以用来研究或分析人的情绪。许多公司正在植入面部表情识别系统来研究员工的抑郁程度。游戏公司也可以应用面部识别系统来记录游戏玩家在游戏过程中的满意度。
本文就是教大家如何在Raspberry Pi 4 上实现应用预训练模型从实时视频流中识别人的面部表情。
-
使用 OpenCV、TensorFlow 和 Keras ,基于 Raspberry Pi 进行情绪识别,你的心情一览无余。
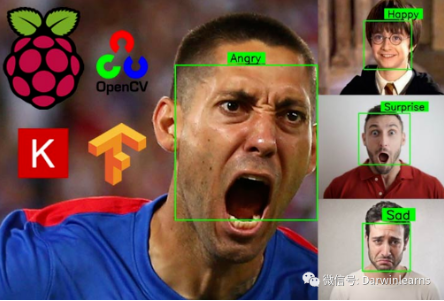
面部表情识别系统可用于多种应用,可以用来研究或分析人的情绪。许多公司正在植入面部表情识别系统来研究员工的抑郁程度。游戏公司也可以应用面部识别系统来记录游戏玩家在游戏过程中的满意度。
下面就是教大家如何在Raspberry Pi 4 上实现应用预训练模型从实时视频流中识别人的面部表情。
✔ 在树莓派上执行面部表情识别的步骤
要在树莓派上实现表情识别,仅需下面三个步骤。
第1步:检测输入视频流中的人脸。
第2步:找到人脸的感兴趣区域 (ROI)。
第3步:面部表情识别模型来预测人的表情。
本项目中使用六个类别,即“愤怒”、“恐惧”、“快乐”、“中性”、“悲伤”、“惊喜”,预测的图像将属于这些类别。
✔ 面部表情识别所需的组件
项目涉及的硬件非常少,只需要2个即可: 树莓派4和Pi摄像机模块,并在Raspberry Pi上安装OpenCV。OpenCV 在这里用于数字图像处理,最常见的应用是物体检测、人脸识别和人数统计。
✔ 在树莓派 4 上安装 OpenCV
在安装 OpenCV 和其他依赖项之前,Raspberry Pi 需要完全更新。使用以下命令将 Raspberry Pi 更新到最新版本:
sudo apt-get 更新然后使用以下命令在 Raspberry Pi 上安装 OpenCV 所需的依赖项。
sudo apt-get install libhdf5-dev -ysudo apt-get install libhdf5-serial-dev –ysudo apt-get install libatlas-base-dev –ysudo apt-get install libjasper-dev -ysudo apt-get install libqtgui4 –ysudo apt-get install libqt4-test –y之后,使用下面的命令在Raspberry Pi 上安装 OpenCV。
pip3 install opencv-contrib-python==4.1.0.25✔在树莓派 4 上安装 TensorFlow 和 Keras
在安装 Tensorflow 和 Keras 之前,请安装以下提到的所需库。
sudo apt-get install python3-numpy
sudo apt-get install libblas-dev
sudo apt-get install liblapack-dev
sudo apt-get install python3-dev
sudo apt-get install libatlas-base-dev
sudo apt-get install gfortran
sudo apt-get install python3-setuptools
sudo apt-get install python3-scipy
sudo apt-get update
sudo apt-get install python3-h5pyTensorflow 和 Keras 库可以通过在终端中使用 pip(如果将 python3 作为 raspberry pi 上的默认 python 环境,则使用 pip3 命令)命令安装。
pip3 install tensorflowpip3 install keras✔ 为面部表情识别编程 Raspberry Pi
在“达尔闻说”微信回复:表情识别,下载完整表情识别代码,也可以从以下链接下载:https://drive.google.com/file/d/1HYqKyhi_wm26AIGMvdHAFR8r6lGHXwiE/view
下面将解释代码的重要部分,以便更好地理解。下载的项目文件夹包含一个子文件夹 (Haarcascades)、一个 Python 文件 (emotion1.py) 和模型 (ferjj.h5)。
通过导入下面提到的重要数据包来启动代码。
注意:这里使用TensorFlow API来导入Keras库。
from tensorflow.keras import Sequential
from tensorflow.keras.models import load_model
import cv2
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array接下来,是使用从 Keras 库导入的load_model()函数加载预训练模型(在项目文件夹中提供) 。在下一行中,创建一个labels并将标签分配给 6 个类。
# We have 6 labels for the model
class_labels = {0: 'Angry', 1: 'Fear', 2: 'Happy', 3: 'Neutral', 4: 'Sad', 5: 'Surprise'}
classes = list(class_labels.values())
# print(class_labels)现在,Haarcascade 分类器的路径是通过使用OpenCV 库中的CascadeClassifier()函数提供的。
face_classifier = cv2.CascadeClassifier('./Haarcascades/haarcascade_frontalface_default.xml')text_on_detected_boxes ()函数可用于设计检测到的人脸的输出标签。text_on_detected_boxes()的参数已经有了它们的默认值,可以根据需要更改这些值。
# This function is for designing the overlay text on the predicted image boxes.
def text_on_detected_boxes(text,text_x,text_y,image,font_scale = 1,
font = cv2.FONT_HERSHEY_SIMPLEX,
FONT_COLOR = (0, 0, 0),
FONT_THICKNESS = 2,
rectangle_bgr = (0, 255, 0)):✔ 在图像上测试我们的面部表情识别:
在face_detector_image(img)函数中, cvtColor()函数用于将输入图像转换为灰度。如下所示,此处拍摄的示例图像被转换为灰度。

然后从图像中提取人脸的感兴趣区域 ( ROI )。该函数返回三个重要因素,即人脸的 ROI、人脸的坐标和原始图像。已在检测到的面部上绘制了一个矩形。将图像转换为灰度并在我们的 ROI 周围绘制一个框的代码如下所示:
def face_detector_image(img):
gray = cv2.cvtColor(img.copy(), cv2.COLOR_BGR2GRAY) # Convert the image into GrayScale image
faces = face_classifier.detectMultiScale(gray, 1.3, 5)
if faces is ():
return (0, 0, 0, 0), np.zeros((48, 48), np.uint8), img
allfaces = []
rects = []
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_gray = cv2.resize(roi_gray, (48, 48), interpolation=cv2.INTER_AREA)
allfaces.append(roi_gray)
rects.append((x, w, y, h))
return rects, allfaces, img在程序的这一部分中,通过提供 ROI 值来应用模型。函数下的前两行用于获取输入图像并将其传递给face_detector_image(img)函数,如上一节所述。
 def emotionImage(imgPath):
def emotionImage(imgPath):
img = cv2.imread(imgPath)
rects, faces, image = face_detector_image(img)
i = 0
for face in faces:
roi = face.astype("float") / 255.0
roi = img_to_array(roi)
roi = np.expand_dims(roi, axis=0)
# make a prediction on the ROI, then lookup the class
preds = classifier.predict(roi)[0]
label = class_labels[preds.argmax()]
label_position = (rects[i][0] + int((rects[i][1] / 2)), abs(rects[i][2] - 10))
i = + 1
# Overlay our detected emotion on the picture
text_on_detected_boxes(label, label_position[0],label_position[1], image)
cv2.imshow("Emotion Detector", image)
cv2.waitKey(0)
cv2.destroyAllWindows()预测后,输出结果与检测到的人脸一起显示。输出结果显示在我们之前创建的class_labels中。使用text_on_detected_boxes()函数来设计检测到的面部上的标签。imshow ()函数用于显示窗口。
✔ 视频流上的面部表情识别:
face_detector_video (img)函数用于检测视频流上的人脸。我们将输入帧作为图像提供给此函数。此函数返回检测到的人脸的坐标、人脸的感兴趣区域 (ROI)和原始帧。rectangle()函数用于在检测到的面上绘制一个重叠的矩形。
def face_detector_video(img):
# Convert image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(gray, 1.3, 5)
if faces is ():
return (0, 0, 0, 0), np.zeros((48, 48), np.uint8), img
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), thickness=2)
roi_gray = gray[y:y + h, x:x + w]
roi_gray = cv2.resize(roi_gray, (48, 48), interpolation=cv2.INTER_AREA)
return (x, w, y, h), roi_gray, img在本节中,将应用我们的模型来识别视频流上的表达,并在视频流上实时显示预测输出。
在前两行中,我们从输入视频流中提取一帧。然后,将帧输入face_detector_video(frame)函数。现在,分类器中的predict()函数用于预测检测到的人脸的表情。然后我们为脸上的每个预测分配class_labels。现在,imshow()用于在每个面上显示带有已识别表情的窗口。
def emotionVideo(cap):
while True:
ret, frame = cap.read()
rect, face, image = face_detector_video(frame)
if np.sum([face]) != 0.0:
roi = face.astype("float") / 255.0
roi = img_to_array(roi)
roi = np.expand_dims(roi, axis=0)
# make a prediction on the ROI, then lookup the class
preds = classifier.predict(roi)[0]
label = class_labels[preds.argmax()]
label_position = (rect[0] + rect[1]//50, rect[2] + rect[3]//50)
text_on_detected_boxes(label, label_position[0], label_position[1], image) # You can use this function for your another opencv projects.
fps = cap.get(cv2.CAP_PROP_FPS)
cv2.putText(image, str(fps),(5, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
else:
cv2.putText(image, "No Face Found", (5, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
cv2.imshow('All', image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()这是代码的主要功能。在主函数中可以使用emotionVideo()函数和emotionImage()函数。如果想在图像上使用面部表情识别,那么只需注释主函数的前两行并取消注释其余两行。但请确保在IMAGE_PA TH 变量中提供输入图像的路径。
if __name__ == '__main__':
camera = cv2.VideoCapture(0) # If you are using an USB Camera then Change use 1 instead of 0.
emotionVideo(camera)
# IMAGE_PATH = "provide the image path"
# emotionImage(IMAGE_PATH) # If you are using this on an image please provide the path✔ 在 Raspberry Pi 上测试我们的面部表情识别系统
在启动 Python 脚本之前,将 Raspberry Pi 相机模块与 Pi 连接,如下所示:

现在,检查 Pi 相机是否正常工作。查看相机后,启动 Python 脚本,会发现弹出一个窗口,其中包含视频源。一旦 Pi 检测到表达式,它将以绿色框显示在视频源上。



-















